Appearance
Risk Agent PREVIEW
The Risk Agent generates a defensible first-pass quantification for a risk threat — a monetary expected loss with the assumptions, drivers, and ranges that produced it. The output is a draft for human review, not a final number.
Preview
The Risk Agent is currently in preview. Outputs are intended to accelerate a human-authored quantification; review the assumptions before accepting them and keep using scenario analysis or Monte Carlo when you need stronger statistical grounding.
What this is
When you run the agent on a threat, it produces:
- a proposed monetary expected loss value
- the assumptions the model relied on (probability, impact ranges, frequency, mitigation effectiveness)
- the drivers and structured references the model used (linked controls, evidence, framework context)
- a short rationale describing how the value was reached
The output is captured as a risk_agent_fermi quantification run alongside the other methods — visible in the Quantification History table, the Risk Value Over Time chart, and the run drawer.
Where in Modulos
You run the Risk Agent from the quantification wizard for a risk threat.
Project → Risks → select a risk → select a threat → Quantify → Select Method → Risk Agent
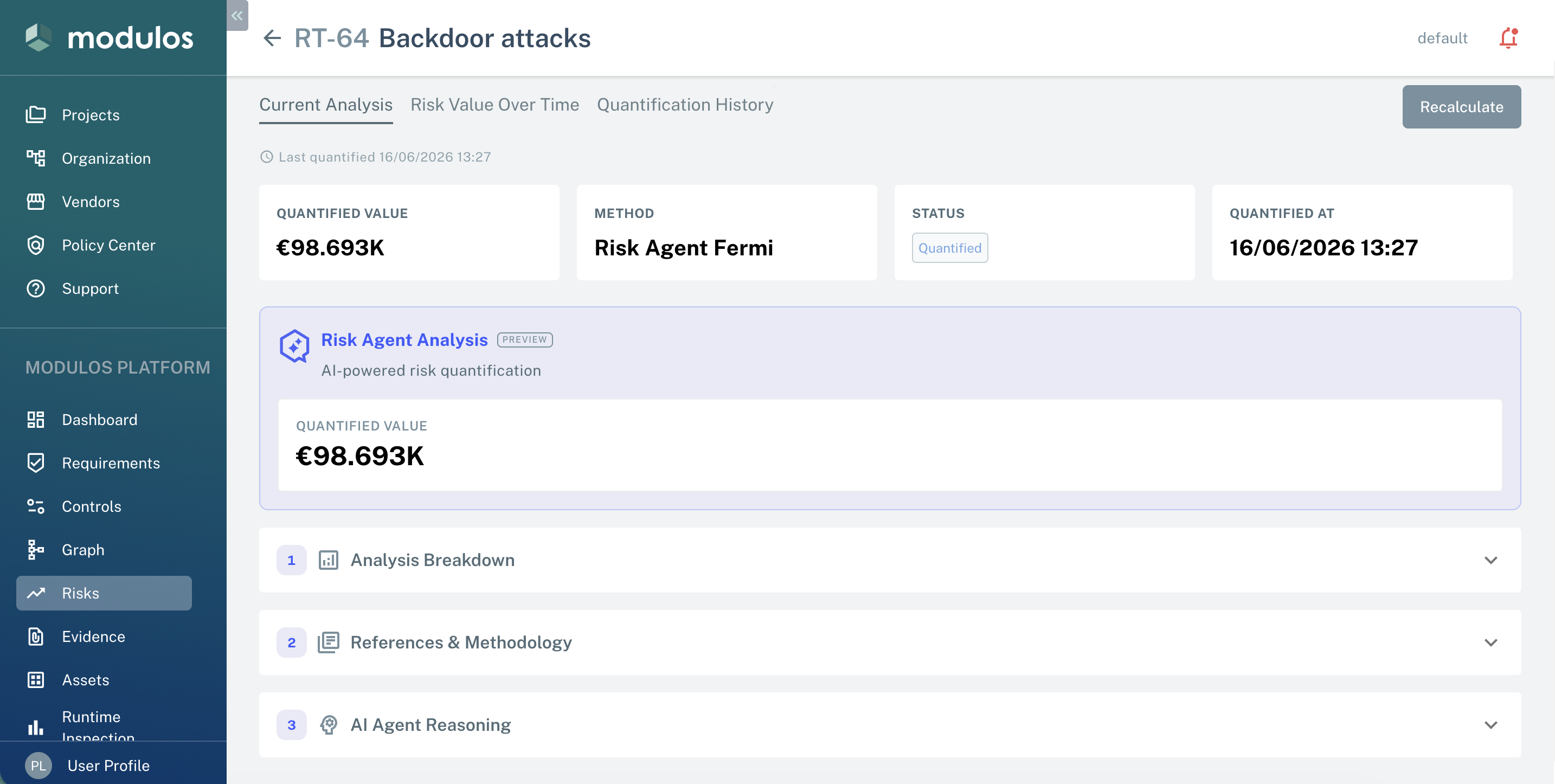
Reading the output
The Risk Agent presents its result as a single output card with three sections. Review them in order — the headline value and its assumptions, the evidence behind it, and the model's own reasoning.
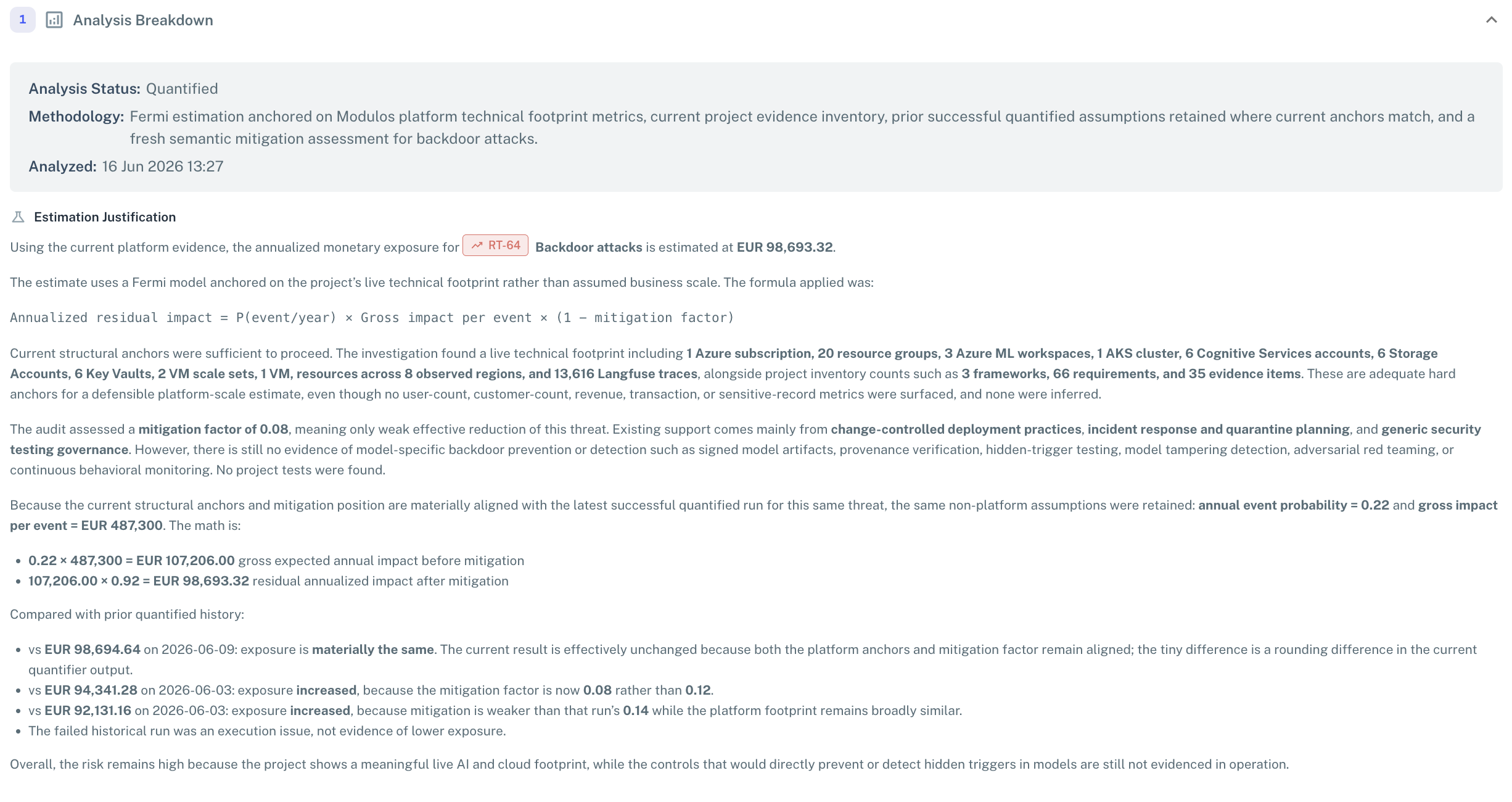
Analysis Breakdown
The proposed monetary expected loss with the methodology and a written justification — the Fermi formula, the structural anchors the agent found, the assessed mitigation factor, and how the value compares to prior runs.
References & Methodology
The structured references the model relied on — frameworks, requirements, evidence items, and controls — and the estimation source that describes how they were combined.

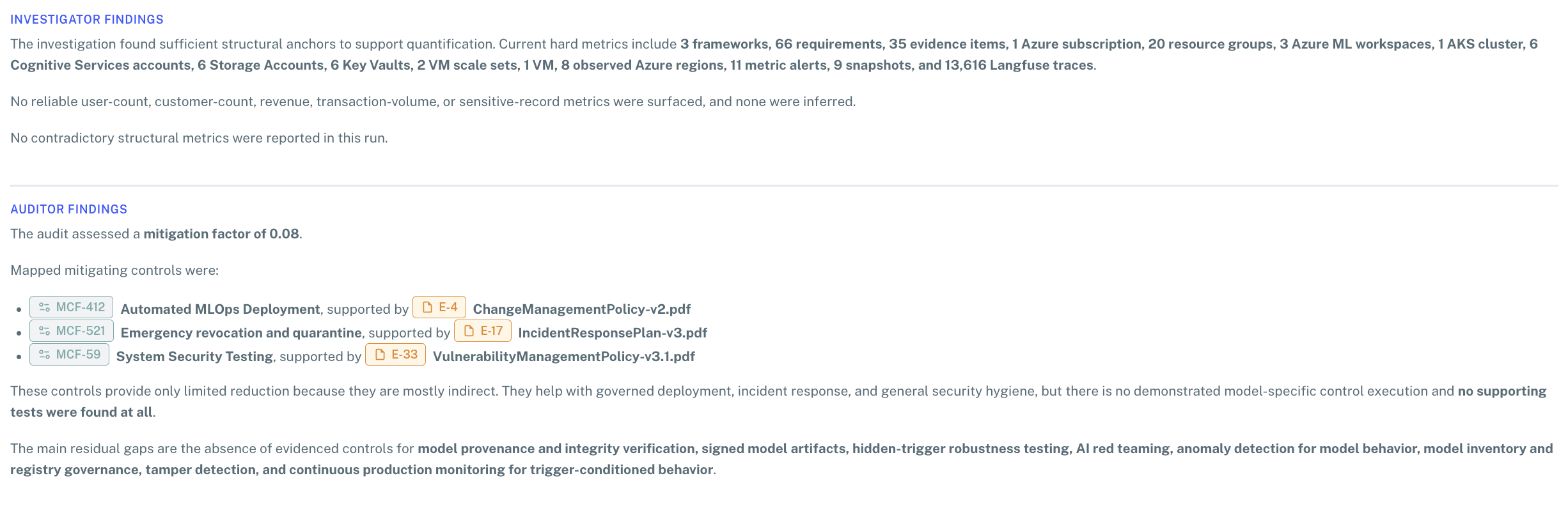
AI Agent Reasoning
The full reasoning trace, broken out by the roles that produced the estimate: a supervisor that frames the run, an investigator and auditor that gather structural anchors and assess mitigation, and a quantifier that does the math. A reviewer can trace every assumption back to its source.


How the agent reasons
The Risk Agent uses the threat context (its description, the linked risk and risk category, the project's framework templates and controls, and any explicitly linked evidence) to assemble a structured estimate. It expresses its reasoning as structured references so a reviewer can trace every assumption back to its source.
When you re-run the agent on the same threat with different inputs (additional evidence, updated controls), it produces a new run with its own assumptions and value — exactly like a Monte Carlo or scenario run. Past runs remain in the history.
Who can do what
Permissions — can run the agent and save runs
- Organization Admin, Risk Manager, or Policy Manager — these organization-level roles have full access to every project in the organization.
- Project Owner on the project.
Permissions — can read saved runs
All of the above, plus Project Editor, Project Reviewer, and Project Auditor on the project. These project roles can walk through Quantification History and the Risk Value Over Time chart but cannot start a new run.
Working with the output
The Risk Agent draft is a starting point, not a verdict.
- Review the assumptions. If a probability or impact range doesn't match what you know, change the inputs and re-run, or switch to scenario analysis to record the structured story explicitly.
- Treat the value as a Fermi estimate. It is order-of-magnitude useful for prioritisation; it is not a substitute for incident-data-backed modelling.
- Re-run as context changes. New evidence or control coverage can shift the agent's read materially. Use the Risk Value Over Time chart to compare runs.
- Keep human accountability. As with the other AI agents in Modulos, the human reviewer remains accountable for what gets saved and reported.
Related pages
Risk Quantification
Conceptual model, workflow, and guardrails
Quantification Methods
Reference for all quantification methods, including the Risk Agent
AI Agents Overview
Where the Risk Agent fits alongside Scout, Evidence Agent, and Control Assessment Agent
Human in the Loop
How AI agent outputs are reviewed, edited, and accepted in Modulos